

















来年もAIバブルは続く 2025年の9大トレンドから動向を予測
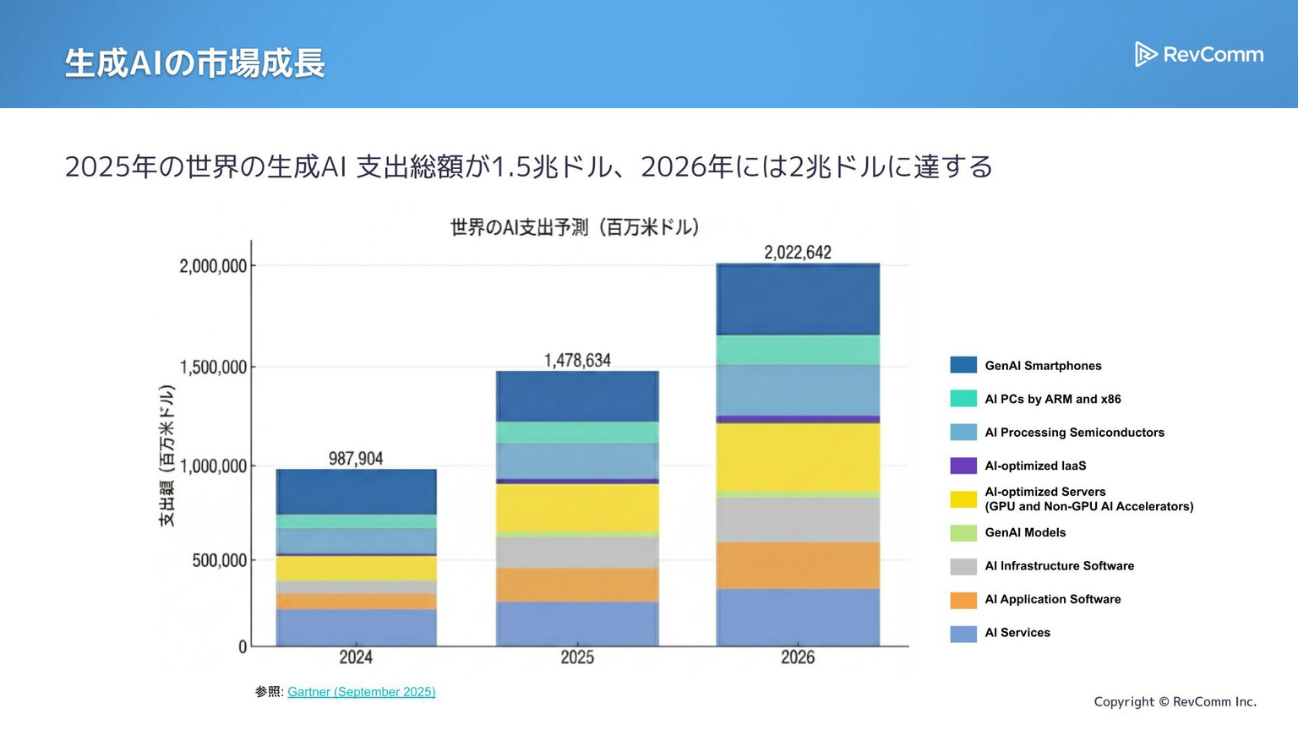
生成AI市場は依然として急速な成長を続けています。2025年の世界の生成AI関連支出総額は、前年の1兆ドルから約1.5倍に拡大し、1.5兆ドルに達しました。さらに2026年には2兆ドルに到達する見込みです(※)。
この市場規模には、生成AIモデルの提供企業はもちろんのこと、訓練・運用のインフラ、そして生成AIを活用した新サービスの成長も含まれます。「AIバブルは終焉に向かうのではないか」という懐疑的な見方もありますが、現在のトレンド予測では、市場はまだ成長の一途を辿ると考えられています。
今年は、昨年に比べて多岐にわたるアップデートが行われました。主要トレンドは主に9つに分けられます。
(1)マルチモーダル化の進展
従来はテキストで入力し、テキストで出力を得るのが一般的だった生成AIですが、テキスト・画像・音声・動画で入力し、同様に複数のメディアで出力を得ることができるようになりました(マルチモーダル化)。
これにより、たとえば「この動画を要約して手順を文書化してほしい」「この動画の内容をナレーションも含めて文章にまとめてほしい」といった複雑な指示が可能となります。技術の進展によって人間が行っている業務の自動化やDX化が進めば、人間とコンピューター(機械)の協業方法の確立が一層求められるでしょう。
(2)エージェント型AI/自律ワークフローの台頭
昨年までは、人間が生成AIに細かく指示を出す活用方法が主流でした。今年からは、生成AIがタスクを受け取り、ステップを自ら考えて自律的に動く「エージェント型AI(Agentic AI)」が本格的に注目を集めました。
特に活用が進んでいるのがソフトウェア開発の分野です。「バグの原因特定/修正プログラム作成/レビュー/本番環境への反映」といった一連の作業の大部分を生成AIが担えるようになりました。現時点ではまだごく一部とはいえ、人間が対応していた業務が生成AIに置き換わる可能性が現実のものになっています。開発生産性の飛躍的な向上と人的負担の軽減の実現が、目の前まできているのです。
一方で、生成AIが自律的に行う「業務の透明性」「説明可能性」「ガバナンス(責任)」といった点が、よりクリティカルな経営課題となります。
(3)非構造化データを構造化データに
テキスト・画像・音声・動画・ソースコード・ログといった非構造化データを、生成AIによって構造化されたデータ資産として扱うことが可能となりました。従来、非構造化データは個別に分析され、データのサイロ化の大きな原因となっていました。これらを統合的に活用できるようになったことは大きな進展です。
今まで多くの企業がDXを推進し、データを蓄積してきたのではないでしょうか。生成AIの進化によって、活用が停滞していたデータから価値を引き出し、企業の競争資源として転用できるようになったといえます。
ただし、生成AIで誤った構造化を行うと、誤情報が量産されるリスクがあります。データの質・バイアス・偏りなどを精査し、適切なラベル付けができているか検証するメカニズムを組み込まなければなりません。
(4)合成データ(Synthetic Data)/データの民主化
生成AIの学習には膨大なデータセットが必要です。しかし、著作権や機密性の問題、あるいは希少性から、実データの入手が困難なケースが散見されます。そこで注目されているのが、生成AI自身が人工的なデータ(合成データ)を生成し、それを用いて生成AIモデルを学習させる技術です。
これにより、データ取得コストの削減、新領域への迅速な対応、医療や教育といったプライバシー保護が求められる分野での安全なデータ確保が可能となります。一方で、現時点では実運用での検証が不足しており、合成データの「本物らしさ」と「偏りのリスク」といった課題に慎重な対応が求められます。
(5)安全性・ガバナンス・説明可能性の強化
生成AIによる出力の偏り・著作権侵害・偽情報の発信といったリスクが増大しています。提供側にも使用側にも、情報の管理および追跡可能性・説明可能性への要求が高まっています。企業が信頼できる生成AIを導入・運用するためには、単なる活用にとどまらず、管理・監査・安全対策を設計して業務に組み込むことが求められるようになっています。
(6)文脈(コンテキスト)処理の拡張
生成AIモデルが扱える「文脈(コンテキスト)」の量が飛躍的に拡大しました。これにより、大量の文書・長時間の会議音声および動画などを一度に扱う能力が標準化されたのです。生成AIが複雑なタスクもこなせるようになりました。法律文や技術仕様書、長時間の会議の議事録、プロジェクト履歴などを一度に処理できるようになったことで、ナレッジ活用や示唆を得るといった業務の質向上につながります。
(7)エッジ/オンデバイス・軽量モデルの拡大
昨年までは、クラウド上での生成AI活用が一般的でした。今年からはスマートフォンやIoTデバイスといった軽量デバイス上で動作する生成AIモデルが登場しています。デバイス上での動作は、データのプライバシー保護・応答速度の短縮・オフラインでの運用を可能にします。これにより、製造現場や機密性の高いフィールドワークなどでも、生成AIの活用が期待できます。
(8)垂直特化・ドメイン特化モデルの隆盛
OpenAIをはじめとした生成AIの汎用モデルを提供する企業に加えて、特定の産業(医療、金融、法律など)や業務プロセスに特化した生成AIモデルが続々と生まれています。汎用モデルをそのまま活用するよりも、ドメイン知識を深く学習させた特化型モデルのほうが、特定の業務における性能とコスト効率の両面で効果が得られます。専門領域における生成AIの適用が本格化しているのです。
(9)環境・持続可能性(サステナビリティ)への配慮
生成AIの訓練・運用には膨大な計算資源とエネルギー消費をともないます。そのため、低消費電力モデルの開発や再利用データの活用、効率的なアーキテクチャの構築といった技術が進展し始めました。今後は性能だけでなく持続可能性も生成AIの評価軸の一つとなり、より少ない計算資源やエネルギー消費で運用できるかが求められるでしょう。