















NTTが、大規模言語モデル(LLM)における入出力単位「トークン」の語彙を精度劣化なく縮小させ、異なるLLM間でもトークン語彙を共通化できる推論技術を確立した。
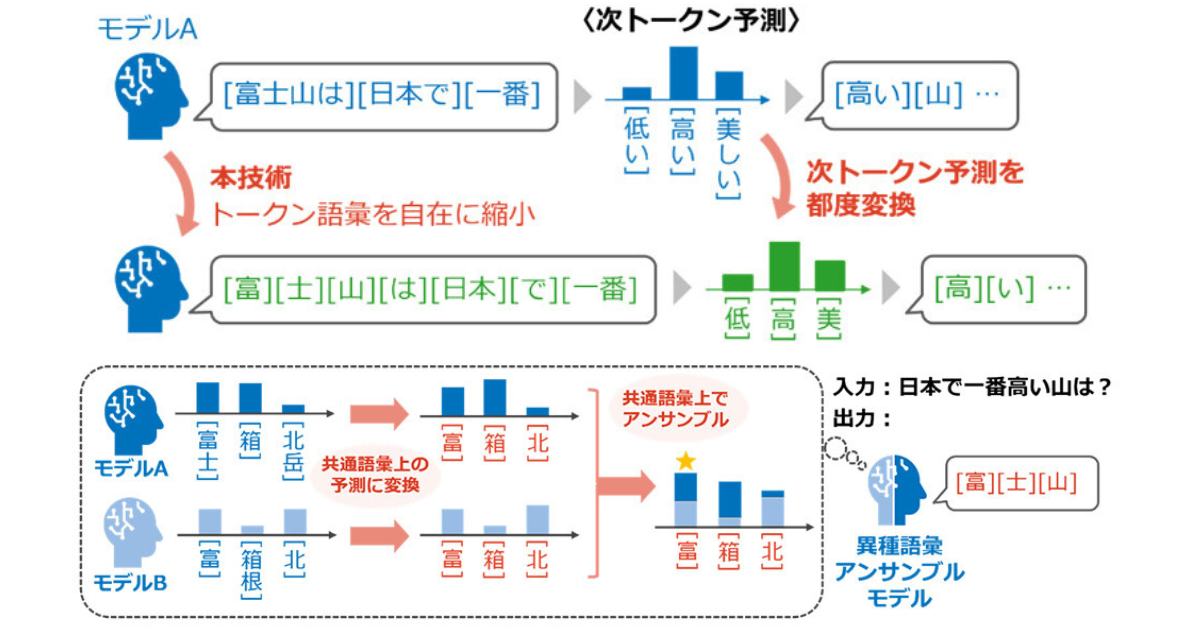
これまで、複数のLLMを用いてアンサンブルに代表される推論時連携を実現するには、各LLMのトークン語彙が一致している必要があった。今回発表された技術によりその制約が解消された。任意の異種LLM間でこれまで困難だったアンサンブルやNTT独自のポータブルチューニングなど様々な推論時連携が可能となり、知識の統合・転移による高精度化を実現できるようになった。
「損失なし」で語彙を自在に縮小させる新理論
単にトークン候補を減らすだけであれば、削りたいトークン候補の情報を次トークン予測から削ることで実現できるが、本来出力されるはずだった文字列が出力されなくなることで、大幅な性能劣化につながる。本研究では、元の語彙に関するトークン確率と部分語彙に関するトークン確率とを統一的に扱える理論的枠組みを構築し、最終的な出力文字列の分布が不変となるために、それらトークン確率の間で満たされるべき関係式を導出したという。この関係式に基づいて元の語彙による次トークン予測を変換していくことで、出力品質は変えずに、部分語彙による次トークン予測が計算可能となった。
実用的な変換アルゴリズムを導出
上記の理論により任意の部分語彙での次トークン予測が計算可能となったが、そのためには元のLLMによる複数の次トークン予測結果が必要で、その計算コストが新たな課題だった。これに対して、計算上必要な複数の次トークン予測のほとんどがキャッシュにより再利用できる点、確率値がほぼ0となる下位トークンは計算上省略できる点を設計に取り入れたとのこと。その結果、元の語彙による通常の推論時と同程度の計算コストで動作する、効率的な変換アルゴリズムを実現したという。なお、本アルゴリズムを実際のLLMに適用し、理論通りに出力傾向を保ったまま、様々な部分語彙での推論が可能となることを確認したとしている。
最大共通語彙による異種LLM間の知識統合を実現
この変換アルゴリズムの応用として、異なる語彙を持つ複数の異種LLMに対し、それらに共通するトークン候補をすべて集めた「最大共通語彙」で推論させた。これにより、異種LLM間で次トークン予測の共有が可能となった。また、実際に語彙の異なるLLM同士に対して共通語彙によるアンサンブルを適用した実験において、出自の異なる知識の統合により単体モデルに比べて推論能力が大幅に向上することが確認できた。
- 関連リンク
この記事は参考になりましたか?
- この記事の著者
-

AIdiver編集部(エーアイダイバーヘンシュウブ)
「AIdiver」(エーアイダイバー)は、株式会社翔泳社が運営する、企業およびビジネスパーソンのAIの利活用にフォーカスしたメディアです。経営、ビジネス、日々の業務をAIで変革したい「AIリーダー」の皆さまに役立つコンテンツを発信します。
※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です
この記事は参考になりましたか?
この記事をシェア